VIDEO: DevOps – střelci s prstem na atomovém tlačítku
DevOps Engineer – co si pod tím představit? Vyzpovídali jsme Jirku Kováře, lídra DevOps týmu. Zjistěte, v čem je DevOps pankáčská disciplína, proč má svůj tým rád a z jakého průšvihu mu ještě dnes vstávají chlupy na předloktí.
Jak se ze mě stal DevOps Leader
Jsem v Kentico přes devět let. Přišel jsem ve dvaadvaceti jako developer do tehdejšího EMS, dnes Kentico Xperience. Pak jsem se posunul na seniora, postupně vyrostl v Technical Leadera a přešel do DevOps týmu. Ten teď vedu v divizi Kontent.
Proč jsem přepnul z vývojařiny na DevOps
Měl jsem od začátku velký přesah do MS Azure a monitoringu. UI není úplně můj koníček, chtěl jsem dělat spíš back-end. Ale stejně jsem si jako nováček UI užil skoro rok. Potřeboval jsem změnu.
Co mě na DevOps nejvíc baví
Jsme hrozní pankáči. To mám rád. Minimum mítinků, žádné rigidní procesy, a přitom společně dokážeme vyřešit skoro jakýkoli problém
.jpg) Chcete důkaz, že DevOpsáci umí řešit problémy flexibilně a mají specifický smysl pro humor? Tady je...
Chcete důkaz, že DevOpsáci umí řešit problémy flexibilně a mají specifický smysl pro humor? Tady je...
Zhruba 50 % naší práce přichází ad hoc. Lidi z některého týmu potřebují pomoc, kdesi v ekosystému vznikne breaking change, bug, performance issue, nebo něco podobného, co musíme objevit a vyřešit. To jsou momenty, kdy zahazujeme plány a jdeme se věnovat těmto důležitým věcem.
Máme samozřejmě stanovenou jasnou vizi, která stojí nad vším, co děláme. Naše portfolio je hodně široké. Ale nejvyšší priorita je prostě co nejvíc zefektivňovat vývoj.
Práce pro vývojáře mě fakt baví – vymyslíš drobnost, která jim ulehčí práci. Vidíš výsledky a dostaneš okamžitou upřímnou zpětnou vazbu.
-(1).png)
Jak si práci organizujeme
Nejsme atomický tým, spíš skupina jednotlivců. S tím souvisí systém plánování. Zatímco ve scrumu tým nabere stories do určitého počtu story pointů, a potom jdou společně věci implementovat, my plánujeme pro jednotlivce.
Málokdy dva děláme na stejné věci. Dlouhodobé úkoly si rozdělíme jednou měsíčně a snažíme se, aby každý z nás měl na starost přednostně to, v čem je dobrý, co ho baví nebo v čem se chce vzdělávat.
Co máme společného je vize, režie každodenního fungování a vzájemné sdílení – nejen v Kontent týmu, ale i napříč divizemi. Na co jsme narazili, s čím mají vývojáři problémy, jak jsme je řešili
Proč musí DevOpsák umět prioritizovat
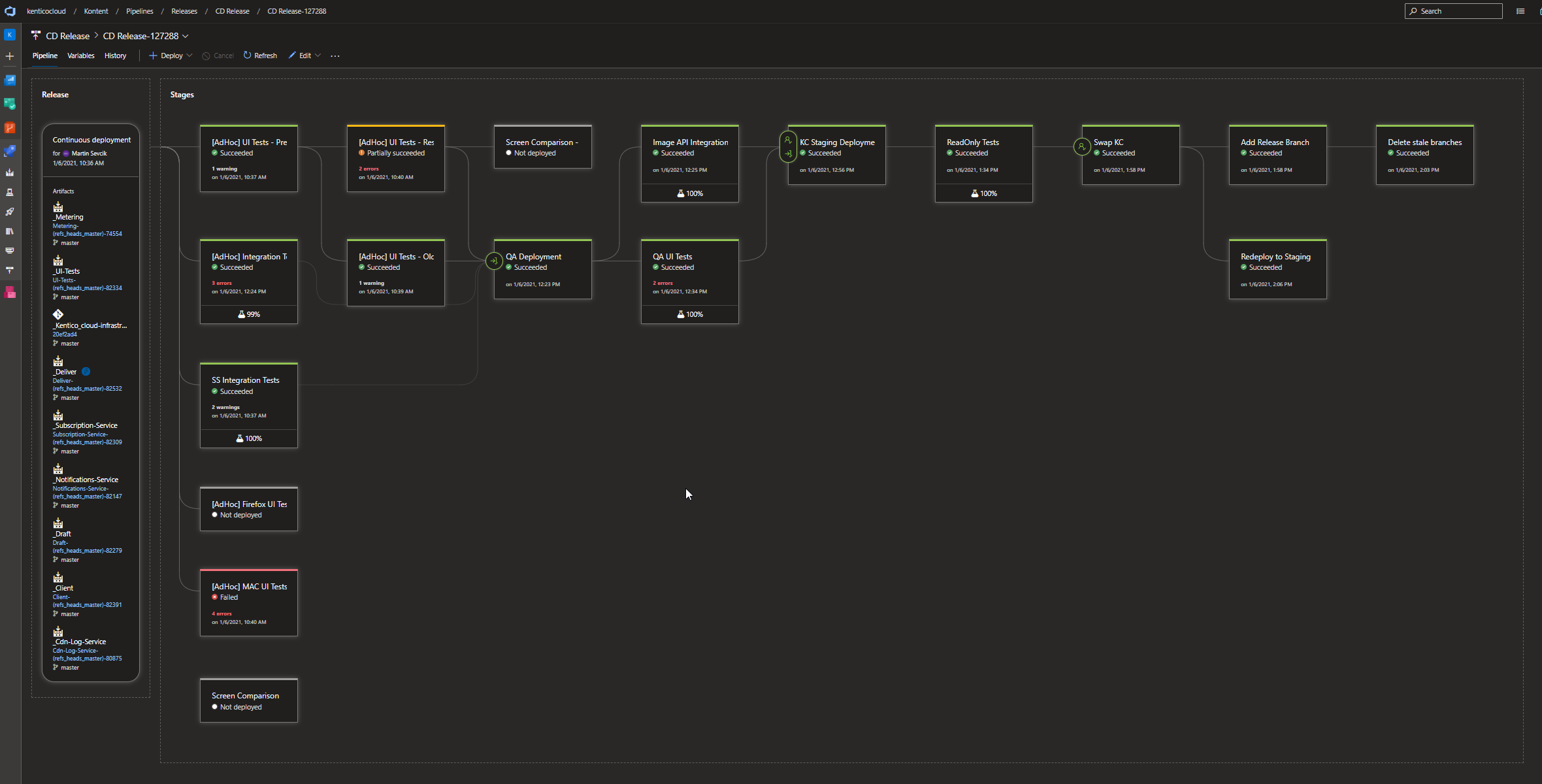
I když nemáme rigidní procesy, plánování nám není cizí. Máme dvě pipeliny. První obsahuje dlouhodobé cíle, vizi, ke které se stále vracíme. V druhé plánujeme drobnější implementační tasky, na kterých pracujeme. A pak jsou tu už zmíněné úkoly, které přicházejí akutně a mimo plán.
Neobejdeme se bez velké samostatnosti. Chodí za námi spousta lidí a my se musíme umět rozhodnout, co má prioritu – jestli to, na čem právě děláme, nebo akutní problém developera.
-(1).png)
Co konkrétně děláme
Vývojáři musí být výkonní, výstup jejich práce musí být dostatečně kvalitní a dostávat se stabilně a efektivně do produkce. Produkce je dostatečně spolehlivá, dobře monitorovaná a zálohovaná. Tohle je v kostce náplní naší práce – na to dohlížíme
V porovnání s konkurencí jsme jako DevOpsáci hodně zaměření vývojářsky. Jsme vlastně developeři, kteří vyvíjejí co nejlepší podporu pro naše vývojáře – tím jsme na trhu práce unikátní, myslím. Nejsme správci serverů, jak to občas bývá jinde, neřešíme nic na síťových vrstvách, virtuální mašiny, clustery atp.
Velkou část práce tvoří psaní kódu – cca 35 % programování v TypeScriptu, 30 % v C#, v tom máme např. chatbota pro výstupy z CI/CD pipeliny a Selenium UI testy. Zbývá zhruba 20 % na programování v Terraformu a 25 % na ostatní – na monitoring, automatizaci konfigurace, Azure DevOps, Azure, Fastly CDN a další.
V rámci monitoringu zajišťujeme, aby všechno v MS Azure klapalo. Dodáváme týmům podporu pro logování a automatizaci alertingu. Když je potřeba, otevřeme si repozitáře a napříč jimi děláme i změny v samotném produktu.
A k tomu spravujeme tooling. Děláme v Azure, Azure DevOps a v Terraform. Snažíme se motivovat i naše vývojáře, aby si v Terraform uměli aspoň trochu poradit sami, ale je jasné, že v něm nejsou tak kovaní.
Samozřejmě se staráme o robustnost produktu a o kvalitu. Snažíme se být podporou vývojářům, pomáháme hasit průšvihy, automatizovat, co jen jde – infrastrukturu nebo konfigurace deploymentu.
Čím se lišíme od klasických vývojářů
Bez znalosti vývoje se neobejdeme ani my. Tam rozdíl není.
Pro DevOpsáka je ale vedle samostatnosti nutná ochota riskovat. S tím jde ruku v ruce odpovědnost – musíme dělat všechno proto, abychom nic v produkci nerozbili.
Chápeme, že naše rozhodnutí může ovlivnit spoustu kolegů, zákazníků, jejich práci. A přitom potřebujeme odvahu taková rozhodnutí denně samostatně dělat.
Člověk se musí sladit se stylem firmy – některé jsou opatrnější, jiné méně.
Protože my jsme ti, co mají červené tlačítko na odpálení atomovky a rádi ho leštíme hadrem od kafe. Každá firma někoho takového má
 S Jirkou se můžete často potkat na konferencích i na našem firemním stánku.
S Jirkou se můžete často potkat na konferencích i na našem firemním stánku.
Jak předcházíme průšvihům
Nad tím červeným tlačítkem máme aktuálně nějakých 5 úrovní zabezpečení, z nichž každé jedno zajišťuje, že k průšvihu nedojde. Často jsme jako DevOpsáci jediní, kdo umí zabezpečení odstranit, kdyby bylo potřeba.
Teď aktuálně máme spoustu rizikových operací automatizovaných, takže chyby lidského faktoru jsme do značné míry odstranili. Ale ne stoprocentně, protože i do automatizace musíš dělat občas zásahy.
Na který fuck-up nezapomenu
Došlo k tomu před lety, od té doby jsme se posunuli úplně jinam.
Dodávali jsme tehdy do produktu multilingual support a datová migrace se rozbila takovým způsobem, že rozhodila zákazníkům data. Jak jsme to opravovali, způsobili jsme nekonzistence v delivery apíčku. Pak jsme do toho apíčka pustili resynchronizaci, což způsobilo, že produkt byl dočasně nedostupný – některým zákazníkům spadl třeba na hodinu web.
To byl hukot – jeden problém vedl na druhý, ten na třetí. A u třetího už jsme byli úplně vyčerpaní, takže nám nedocvaklo, že odstřelíme weby.
Ovlivnilo to i náš Kontent web a HR web. Honem jsme lítali na HR, „hele podívejte se na to, prosím vás, jestli teď už je to v pohodě.“ Třešnička na dortu byla, že zrovna měli mítink s Petrem Palasem.
To člověk už nechce zažít a poučí se nadosmrti.
Jak mě fuck-up ovlivnil
Začal jsem být pragmatický pesimista – počítám předem s tím, že cokoli se může pokazit. Díky tomu nepanikařím a jdu prostě problém konstruktivně řešit
Až po vyřešení přichází upřímná komunikace: „Podělal jsem to, jsem d****, vysvětlím všechno, co bylo špatně a jaké to má dopady.“
Společně se bavíme, jak zajistíme, aby se fuck-up neopakoval. A to je největší přínos – posuneme se dál.
-(1).png)
Proč máme rádi kolegy, kteří už něco rozbili
Každý někdy udělá chybu. A pokud DevOpsák něco takového nezažil, podezírám ho, že nemá za sebou moc zkušeností. Nebo není ochotný riskovat.
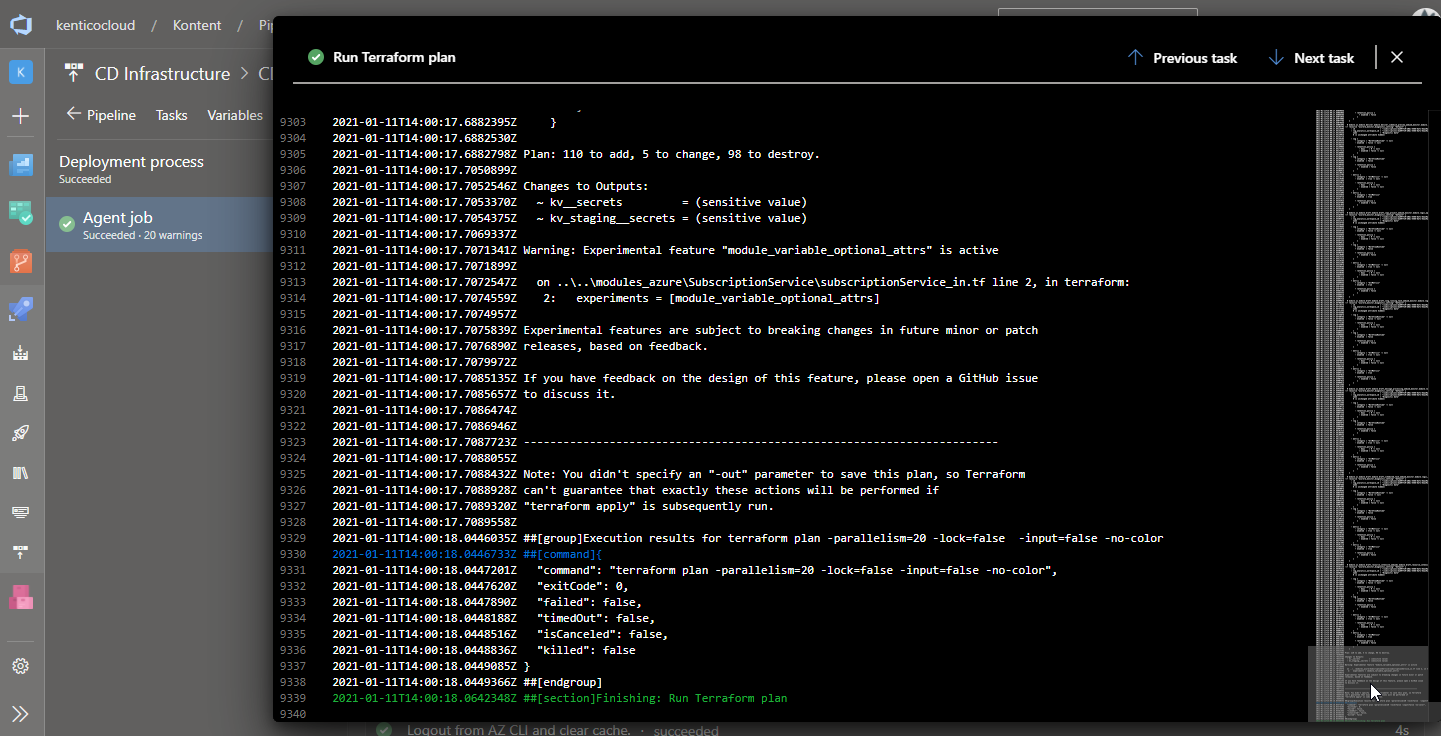
Dám vám příklad. Terraform mi vypisuje seznam změn v produkční infrastruktuře, který má třeba 80 tisíc řádků. V tu chvíli musím položit na vážky efektivitu a preciznost – nemůžu se na něm úplně zasekat. Takže klidně ve dvou projdeme kritické části, u zbytku jen v rychlosti proletím názvy služeb, kterých se to dotkne a ujistím se, že tam není něco nečekaného. Ale pak to musíme odpálit a jít na další úkol. Nemůžu zastavit vývoj jen proto, že mám strach.
Kdo k nám do týmu dobře zapadne
Představuji si člověka, který má drive, zájem o technologie, široký rozhled. A práce ho prostě baví. Takový člověk má ohromný potenciál, když je navíc ochotný dál na sobě makat. Například vývojář, který je hodně zaměřený na back-end, ale nehrne se do UI.
Zároveň má rád zákazníky na dosah ruky a dokáže se s nimi pobavit na rovinu, někdy si s nimi i zanadávat. Naši zákazníci jsou většinou kolegové ve firmě, to je super.
O schopnosti prioritizovat, samostatnosti a ochotě riskovat jsem už mluvil.
Jak bych DevOpsáky v Kentico popsal jedním slovem
Jsou to dříči. Fakt se snažíme lidem dodávat, co potřebují. Jdeme tvrdě po výsledcích, ne po procesech
Co mi v poslední době udělalo radost
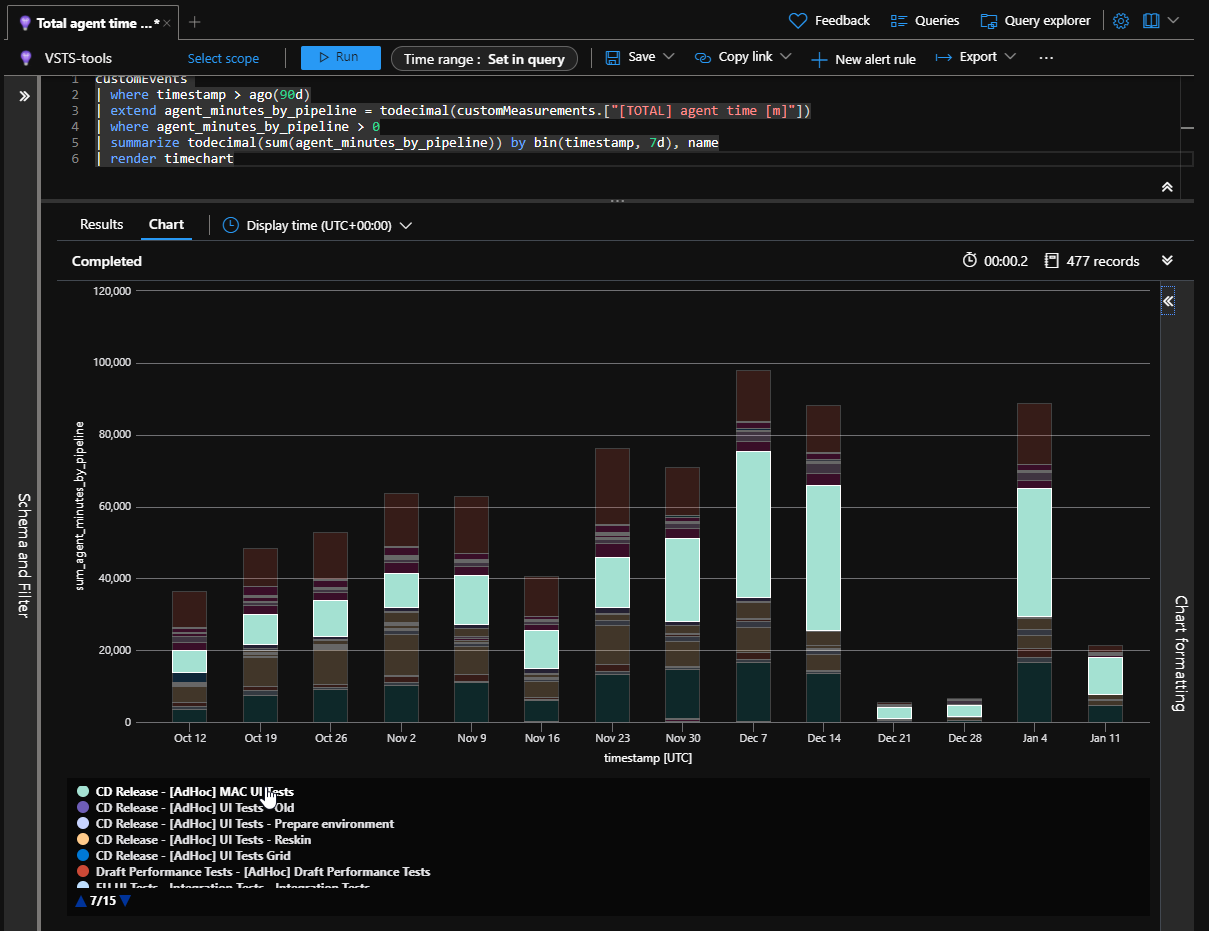
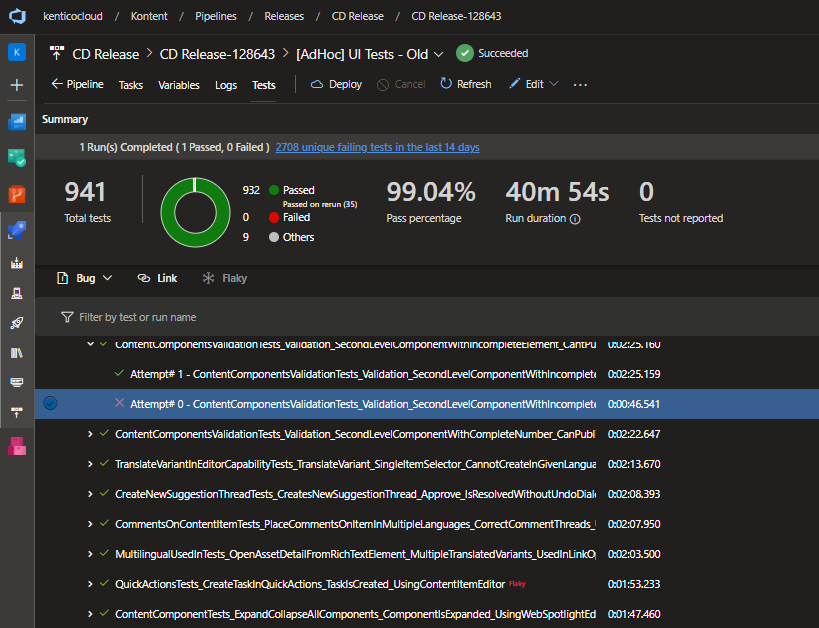
Dokázali jsme zas o kus posunout infrastrukturu. Konkrétně pomocí Selenium Gridu dokážeme vývojářům dodávat výsledky UI testu ještě rychleji, přesněji a efektivněji. Dříve nám pouštění UI testů vytěžovalo agenty z CI/CD pipelines a nedokázali jsme efektivně využít všechny zdroje našeho interního datacentra. Ale teď jsme s použitím Selenium Gridu tyhle nevýhody odstranili; propustnost UI testu narostla přibližně 5×.
Co mě štve
Upřímně? Nestabilita služeb třetích stran, kterou nemůžu ovlivnit.
Kentico nemá ve zvyku schovávat se za třetí stranu. Pokud se kvůli ní zákazníkovi cokoli pokazí, okamžitě to řešíme bez ohledu na to, jestli je to naše vina. A pokud s tím nepohneme, obratem zakládáme třetí straně ticket a tlačíme na nápravu.
-(1).png)
V čem jsem za 9 let v Kentico nejvíce vyrostl
Mám rád MS Azure a nebýt v Kentico, neměl bych v Brně šanci důkladně k téhle technologii přičichnout.
Taky jsem se hodně posunul v měkkých dovednostech. Ono to nevypadá, ale jsem teď fakt o hodně něžnější než dřív. Hrany se mi obrušují, umím věci říkat kulantněji, i když pořád na rovinu.
Pozice lídra mi najednou předkládá nové možnosti i povinnosti. A firma mi umožňuje růst. Vím, že mám rezervy ve spoustě věcí, ale vím, že mám taky jenom určitou kapacitu. Jdu si za zlepšením krok za krokem
Teď mám třeba se Zbyškem domluvený rychlokurz k neagresivní komunikaci.
Kde nás vidím za měsíc
Nastupují k nám dva noví QA inženýři, tak se zvýší zastupitelnost.
… za rok
Dál rozšíříme tým, a tak bude prostor víc se zaměřit na dlouhodobou vizi. A budeme úspěšně pokračovat ve spolupráci DevOps napříč divizemi. V týmu jsou skvělí kluci, se kterými si vzájemně rozumíme. Navíc nás naplňuje tahle práce i po stránce technologické.
… a za pět let
Budeme mít mnohem víc zákazníků, především těch enterprise. Ruku v ruce s nárůstem klientů půjde větší množství datových center, širší ekosystém a infrastruktura. Stále pro nás bude nejdůležitější přinášet zákazníkům hodnotu kvalitního, stabilního a robustního produktu. A udržíme si ochotu riskovat.
Autor
Kde jste se s Jirkou mohli potkat?
Přednáška: DevOps 101
Kentico Dev Meetup #2 | Jiří Kovář, DevOps Leader | 01-2021
Jirka vám bude 45 minut předávat své zkušenosti. Hned poté přijde řada na dotazy. Odnesete si základní informace, které vám poodhalí, z čeho se skládá náš každodenní chleba a jak se stát úspěšným DevOpsákem / úspěšnou DevOpsačkou (nejen) v Kentico.
Přednáška: Azure DevOps Terraform QA FTW
WUG Days 2019 | Jiří Kovář, DevOps Leader
Jak jsme se zbavili stabilně běžícího vývojového prostředí a zajistili, aby si každý vývojář mohl během pár minut vytvořit vlastní izolované prostředí pro svoje branche. Jak jsme prostřednictvím těchto změn dali do rukou vývojářům nástroje, které jim umožňují mergovat a samostatné vydávat lépe ověřený software, zlepšili jejich informovanost o aktuálním stavu a u toho jen tak mimochodem zavedli kompletní automatizaci infrastruktury, konfigurace a ještě u toho ušetřili za cloudove služby.